Distributed Computing
Table of Contents
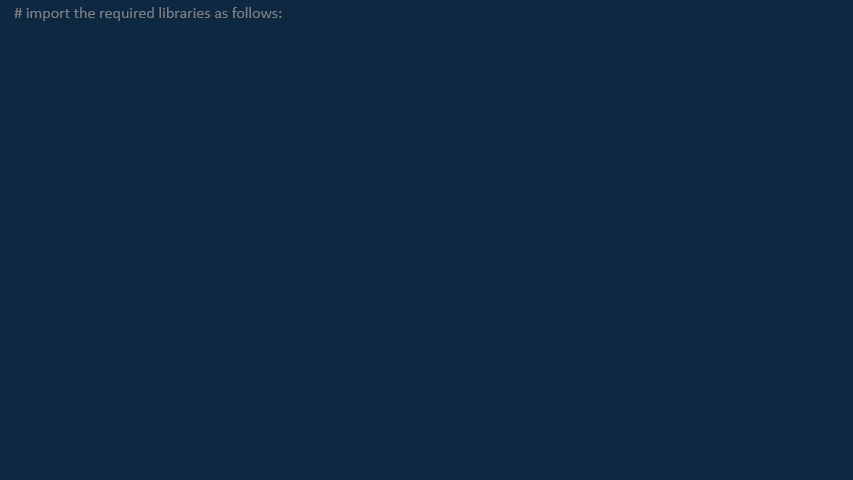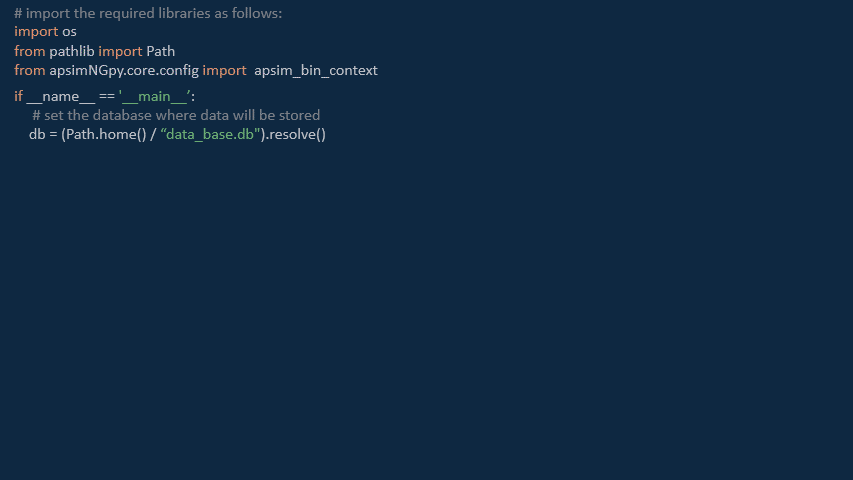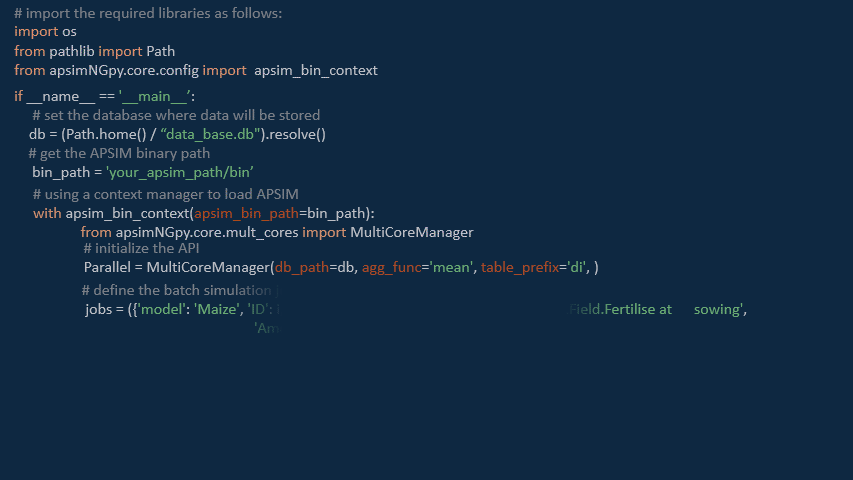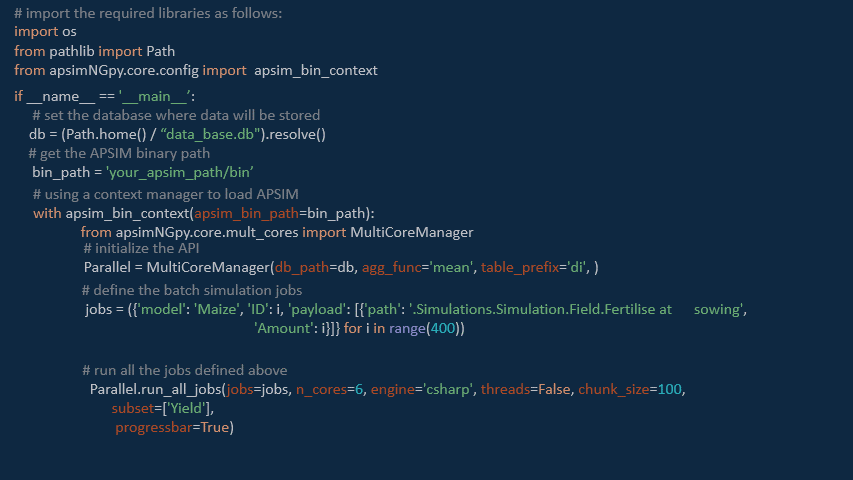
What is distributed computed ?
Distributed computing (or parallelism) is the practice of dividing computing tasks among multiple processing resources to speed up computations. See Li, Z., Qi, Z., Liu, Y., Zheng, Y., & Yang, Y. (2023). A modularized parallel distributed High–Performance computing framework for simulating seasonal frost dynamics in Canadian croplands. Computers and Electronics in Agriculture, 212, 108057.
In apsimNGpy, this is achieved through the MultiCoreManager API, which abstracts away most of the setup required for distributing tasks.
Below, we’ll walk through a step-by-step example of using this API
from apsimNGpy.core.multi_cores import MultiCoreManager
from apsimNGpy.core.apsim import ApsimModel
from pathlib import Path
In this example (v0.39.03.11+), we assume your APSIM files are already prepared (or available in various locations) and you simply want a speed boost when running them and processing results. For demonstration purposes, we’ll generate some example jobs:
# Best to supply a generator so jobs are created on the fly
create_jobs = (
ApsimModel('Maize').path
for _ in range(100)
)
Here we use the ApsimModel class to clone from the template Maize model shipped with APSIM. If you do not specify the out_path argument, each file is assigned a random filename. This is critical in multi-processing—you must ensure that no two processes share the same filename, otherwise the run will fail.
To explicitly set unique filenames for each simulation:
create_jobs = (ApsimModel('Maize', out_path = Path(f"_{i}.apsimx").resolve()).path
Tip
The key idea: every file must have a unique identifier to avoid race conditions during parallel execution.
Job batching
In newer apsimNGpy versions, each job must specify the APSIM .apsimx model to execute and may
include additional metadata.
Supported job definitions include:
1. Plain job batching (no metadata, no edits)
This assumes that each model file is unique and has already been edited externally.
jobs = {
'model_0.apsimx',
'model_1.apsimx',
'model_2.apsimx',
'model_3.apsimx',
'model_4.apsimx',
'model_5.apsimx',
'model_6.apsimx',
'model_7.apsimx'
}
Note
In the newer apsimNGpy version v1.1.0+, when engine=’csharp’, jobs must be defined with ID description see below
2. Job batching with metadata
This format allows attaching identifiers or other metadata to each job. Models are assumed to be unique and pre-edited.
[
{'model': 'model_0.apsimx', 'ID': 0},
{'model': 'model_1.apsimx', 'ID': 1},
{'model': 'model_2.apsimx', 'ID': 2},
{'model': 'model_3.apsimx', 'ID': 3},
{'model': 'model_4.apsimx', 'ID': 4},
{'model': 'model_5.apsimx', 'ID': 5},
{'model': 'model_6.apsimx', 'ID': 6},
{'model': 'model_7.apsimx', 'ID': 7}
]
3. Job batching with internal model edits
In this format, each job specifies an inputs list with dicts representing each node to be edited internally by the runner. These
edits must follow the rules of edit_model_by_path(). The input dictionary is treated as metadata and is attached to the results’ tables. When both inputs and additional metadata are provided, they are merged into a single metadata mapping prior to attachment, with former entries overriding earlier metadata keys and thereby avoiding duplicate keys in the results’ tables.
jobs= [
{
'model': 'model_0.apsimx',
'ID': 0,
'inputs': [{
'path': '.Simulations.Simulation.Field.Fertilise at sowing',
'Amount': 0
}]
},
{
'model': 'model_1.apsimx',
'ID': 1,
'inputs': [{
'path': '.Simulations.Simulation.Field.Fertilise at sowing',
'Amount': 50
}]
},
{
'model': 'model_2.apsimx',
'ID': 2,
'inputs': [{
'path': '.Simulations.Simulation.Field.Fertilise at sowing',
'Amount': 100
}]
}
]
Instantiating and Running the batches
if __name__ == '__main__': # a guard is required
# create jobs
create_jobs = (ApsimModel('Maize', out_path = Path(f"_{i}.apsimx").resolve()).path
# initialize
task_manager = MultiCoreManager(db_path=Path('test.db').resolve(), agg_func=None)
# Run all the jobs
task_manager.run_all_jobs(create_jobs, n_cores=16, threads=False, clear_db=True)
If agg_func is specified, it can be one of: mean, median, sum, min, or max. Each results table will then be summarized using the selected aggregation function.
clear_db is used to clear the database tables before all new entries are added
threads (bool): If True, use threads; if False, use processes. For CPU-bound tasks like this one, processes are preferred as they prevent resource contention and blocking inherent to threads.
n_cores (int): Specifies the number of worker cores to use for the task. The workload will be divided among these workers. If the number of cores is large but the number of tasks is small, some scheduling overhead will occur, and workers may remain idle while waiting for available tasks.
Tracking completed jobs
MultiCoreManager API displays the number of completed jobs and percentage of the total submitted, time per simulation(sim) failed jobs (f) elapsed time and seconds per sim
APSIM running![0f] : |██████████| 100.0%| [100/100]| Complete | 1.07s/sim | Elapsed time: 00:01:46.850
Retrieving results
Results can be loaded to memory by get_simulated_output() or results
df = task_manager.get_simulated_output(axis=0)
# same as
data = task_manager.results # defaults is axis =0
Results can also be transferred to an sql database or to csv as follows
from sqlite2 import connect
db = connect(':memory:")
or
db = 'test.db"
task_manager.save_tosql(db_or_con=db, table_name='agg_table', if_exist='replace', chunk_size=1000)
# to scv
task_manager.save_to_csv('test.csv')
csharp or python engine selections
The latest apsimNGpy versions allows the user to select between python or csharp engine as follows.
In addition any of the word inputs or payload are accepted while providing the editing data.
Parallel = MultiCoreManager(db_path=db, agg_func='mean', table_prefix='di', )
Parallel = MultiCoreManager(db_path=db, agg_func='mean', table_prefix='di', )
jobs = ({'model': 'Maize', 'ID': i, 'payload': [{'path': '.Simulations.Simulation.Field.Fertilise at sowing',
'Amount': i}]} for i in range(200))
start = time.perf_counter()
Parallel.run_all_jobs(jobs=jobs, n_cores=8, engine='csharp', threads=False, chunk_size=100,
subset=['Yield'],
progressbar=True)
dff = Parallel.results
Yield source_table ID Amount MetaProcessID
80 1747.866065 Report 0 0 63672
81 1773.798050 Report 1 1 62028
40 1792.630425 Report 2 2 60976
3 1822.193813 Report 3 3 36152
184 1854.471650 Report 4 4 13056
.. ... ... ... ... ...
103 5602.499247 Report 195 195 57804
94 5601.896106 Report 196 196 61980
93 5601.294697 Report 197 197 69492
130 5600.687519 Report 198 198 64844
101 5600.078263 Report 199 199 66580
[200 rows x 5 columns]
Note
To specify pure python we use the string python as follows:
Parallel.run_all_jobs(jobs=jobs, n_cores=8, engine='python', threads=False, chunk_size=100,
subset=['Yield'],
progressbar=True)
Out[4]:
Yield MetaProcessID ID Amount MetaExecutionID
0 1747.866065 5572 0 0 09f90023a10aa7408899b57e420180b7
0 1773.798050 60752 1 1 1
0 1792.630425 69532 2 2 2
0 1822.193813 59972 3 3 3
0 1854.471650 47032 4 4 4
.. ... ... ... ... ...
24 5602.499247 68876 195 195 195
24 5601.896106 69532 196 196 196
24 5601.294697 69432 197 197 197
24 5600.687519 47032 198 198 198
24 5600.078263 5572 199 199 199
[200 rows x 5 columns]
When no aggregation is applied, the number of rows increases because each simulation contributes multiple records. For example, if each simulation spans 10 years, the resulting DataFrame will contain 10 × 200 = 2,000 rows.
Benchmarking computation speed across the different simulation engines
Batch size |
Python (m) |
C# (m) |
Speedup (×) |
|---|---|---|---|
100 |
2:30 |
1:25 |
~1.76 |
200 |
4:44 |
2:54 |
~1.63 |
300 |
7:13 |
4:23 |
~1.65 |
400 |
9:24 |
5:26 |
~1.73 |
500 |
11:55 |
6:58 |
~1.71 |
m = minutes, C# =csharp
Note
Benchmark results were generated on the following system:
Processor: 12th Gen Intel® Core™ i7-12700 @ 2.10 GHz
Installed RAM: 32.0 GB (31.7 GB usable)
System type: 64-bit operating system, x64-based processor
Tip
Reported speedups are indicative and may vary depending on system hardware, operating system, available memory, number of CPU cores, background workload, and simulation configuration.
See also
API description:
MultiCoreManagerrun_all_jobs API:
run_all_jobs